Chapter 2 - Data Continuity
Contents
Chapter 2 - Data Continuity#
Not every data gap is as obvious as this one…
Chapter preview#
Learning objectives#
Systematize understanding of data (dis)continuity issues (i.e., data gaps) and the types of data gap remediation strategies.
Develop logic for making decisions related to the design and implementation of remediation strategies.
Explore how choice of remediation strategy can impact downstream analysis.
Key question: When data is incomplete and/or messy, how should we think about “fixing” it?
Chapter prerequisites: Python imports#
Before running any code blocks in the following chapter, please ensure you have the necessary Python packages installed via the following code block:
# commented calls may be included in your base install of Python; uncomment call(s) as necessary
%pip install pandas
%pip install numpy
%pip install sklearn
%pip install matplotlib
%pip install random
%pip install dateutil.parser
%pip install datetime
2.0. Preface: Consequences of following data sourcing best practices#
If you follow all of the data sourcing best practices previously discussed (click here if you haven’t reviewed data sourcing yet!), it’s likely that you’ll encounter a data resource that is less immediately “usable” than we might hope.
Although this is a natural consequence of prioritizing factors like data author credibility and reputable data generation approaches over usability, it’s still an unfortunate obstacle to analysis. Besides administrative barriers like paywalls, institutional access, one of the most common obstacles we’ll encounter when using responsibly-sourced, real-life data is data gaps, or a lack of data continuity.

When a delightful children’s classic goes data science!
2.1. Defining “data continuity”#
Data continuity refers to the completeness of a chosen data resource across a given dimension of analysis. Specific data points or ranges of your dimension of analysis where the chosen data resource is missing/incomplete are referred to as data gaps.
Pertinent sub-issues in the practice of addressing data (dis)continuity include data gap:
identification (where are any data gaps present in the dataset?);
comprehension (why are those data gaps where they are in my dataset?); and
remediation (how can I work around these data gaps).
Of these issues, data gap remediation will be the primary focus of this chapter.
DISCUSSION 1: IDENTIFYING & COMPREHENDING DATA GAPS#
Data gap identification often occurs as an (un)intended consequence of attempted analysis, and data gap comprehension can be performed ad hoc using practices similar to those discussed in the data sourcing chapter. Of course, properly addressing each of these sub-issues is important and can be tricky in its own right (e.g., unintentionally writing code that generates figures which mask data gaps). If you’re concerned with your handling of these sub-issues, I encourage you to schedule a consult with SSDS.
And, a final caveat: in line with our running examples using GDP data, we’ll almost entirely be discussing data gap remediation in the context of timeseries data. Data gaps can look very different with regard to other dimensions and types of data (e.g., lack of participants representing population X in a sample, missing attributes for an entry in a specific timeslice of panel data) - however, the thinking practiced during our exploration of how remedying data gaps can impact downstream analysis should be useful nonetheless.
2.2. Remediating data gaps#
When working with messy, real-life data, data gap remediation is one of the practices with the most tangible effects: performed correctly, it enables for an accurate and full scope of analysis. However, when done incorrectly, it can skew results and at worse, invalidate conclusions. Thus, taking the time to (1) systematize and (2) broaden our understanding of the exercise is well-advised.
DISCUSSION 2: TYPES OF REMEDIATION PRACTICES#
Remediation practices can broadly be classified into two categories:
Data gap omission - the exclusion any data gaps from your scope of analysis, limiting any results and conclusions to the present data ranges.
Data gap filling - the use of other data points in the native or external dataset(s) to impute values for any data gaps in your dataset occuring in the desired scope of analysis.
When practicing data gap omission, note that it’s certainly permissible (and likely recommended) to extrapolate your results from the readily available scope of analysis to whatever data ranges are missing. The key difference between the two categories is the quantitative versus qualitative nature of as well as the research community confidence in the accuracy of said extrapolation.

Data gap omission (avoidance) vs. Data gap filling - Pothole Edition
Since data gap omission is not especially programatically interesting (e.g., you simply include a command to skip/omit any data with a NA, NaN, etc. during the data intake process) and its consequences on downstream analysis are fairly one-dimensional (i.e., you can’t draw definitive conclusions over the missing data ranges), we’ll zoom in on data gap filling in future sections.
However, both categories of remediation practices have valid use cases as well as benefits and drawbacks - take a moment to review or add to the table below!
Table 3. Pros and Cons of Data Remediation Strategies
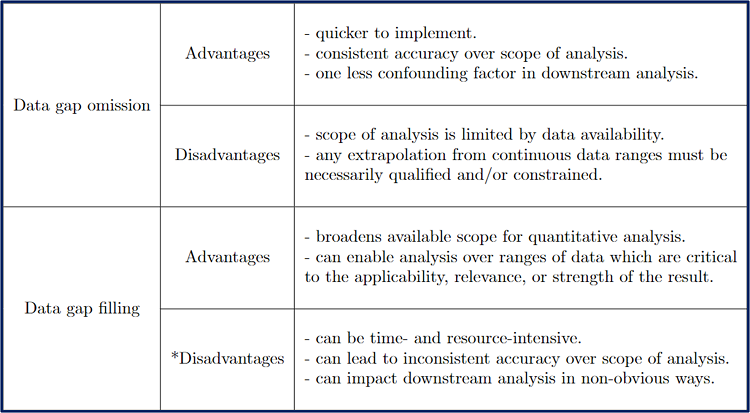
Hopefully you noticed the conspicuous asterisk prefixing the “Disadvantages” sub-section for the “Data gap filling” entry in the table (if not, you can take a look now - the notebook isn’t going anywhere 🙂). As we continue on, I hope to convince that one of the noted disadvantages (“can impact downstream analysis in non-obvious ways”) can at least be partially mitigated by intelligent and intentional design.
DISCUSSION 3: TYPES OF DATA FILL METHODS#
However, prior to that discussion, we first can further systematize our use of data remediation techniques by dividing data gap filling strategies into two types of fill(ing) methods:
Exogenous fill methods utilize an external data source to populate some or all of the discontinuities in your master dataset.
Endogenous fill methods apply statistical methods to the present points in your master dataset to generate estimated values for some or all discontinuities.
Here are some quick definitions-through-code:
CODING EXERCISE: (ENDO)(EXO)GENOUS DATA FILL EXAMPLES#
# shared imports:
import pandas as pd # use: data import & wrangling.
""" DEF: EXOGENOUS FILL METHODS: """
# some toy (ha!) data:
master_data = [[2008, 'puzzles'], [2010, 'Nerf football'], [2012, 'game console']]
# view & construct a DataFrame around the toy data
df = pd.DataFrame(master_data, columns=['Year', 'B-day Toy'])
df
def list_toys_received(df):
for year in range(2008, 2013):
# find the matching dataframe row:
match = df.index[df.Year == year]
# print out the year + toy data for each year:
if len(match) == 0:
print("We don't have data for this year!")
else:
print("Year: {year}; Toy received for Birthday: {toy}".format(year = df.loc[match]['Year'].values, toy = df.loc[match]['B-day Toy'].values))
# what did this person get every year?
list_toys_received(df)
# we don't what this person got for the years 2009 & 2011! exogenous data fill to the rescue.
add_df = pd.DataFrame(data=[[2009, 'clothes'], [2011, 'mobile phone']], columns=['Year', 'B-day Toy'])
print(add_df)
# here, the mechanics of the exogenous data fill operation are as simple as:
franken_df = pd.concat([df, add_df]).sort_values(by='Year', ignore_index=True)
# is our list complete now? let's check!
list_toys_received(franken_df)
# new required imports:
import matplotlib.pyplot as plt # use: data viz.
""" DEF: ENDOGENOUS FILL METHODS: """
# here's some made up timeseries data:
ts_data = [[2000, 43.2], [2001, 45.6], [2002, None], [2003, 39.8], [2004, 44.2], [2005, None], [2006, 45.8], [2007, 52.1]]
# spin up & view a quick DataFrame:
df = pd.DataFrame(ts_data, columns=['Year', 'Amount'])
df
# if we try to make a quick line chart of the data, we'll notice some missing values:
plt.plot(df.Year, df.Amount, linestyle='-', marker='o')
# we can use the existing data points to estimate values for the missing ones! endogenous data filling~
vals = df.Amount.to_list()
for idx, val in enumerate(vals):
# here, our fill method will be the average of the two adjacent values
if pd.isna(val):
vals[idx] = round((vals[idx + 1] + vals[idx - 1])/2, 1)
# let's see our new data!
print("Filled data: {vals}".format(vals = vals))
# and, our new plot & dataframe!
df.Amount = vals
df
plt.plot(df.Year, df.Amount, linestyle='-', marker='o')
DISCUSSION 4: ENDOGENOUS VS. EXOGENOUS FILLS#
Typically, when presented with two separate methods, classes, or ideology, we’ve considered the merits and drawbacks of employing either to help develop criteria for using each one. However, unlike a division like data gap filling versus data gap omission, exogenous and endogenous fill methods are not inherently incompatible.
Depending on your data’s structure and attributes as well as the nature of the discontinuities, you could very well employ both exogenous and endogenous fill methods to remediate different data gaps in the same dataset! This follows from both remediation strategies sharing a primary purpose: to provide accurate estimations within data gaps to enable broadened downstream analysis.

Tag teams: for both data gap remediation and one of hip hop’s greatest single’s!
To help you decide which remediation strategy is best to fill which data gap, we can look to the key sub-issues and potential problems of using each one. Then, in your own research, you can evaluate which sub-issues or problems will give rise to greater inaccuracy, less tractability, etc. to help you make this decision. Let’s get started!
2.3. Issues with exogenous fill methods#
Exogenous fill methods are (generally) less statistically-oriented than their endogenous counterparts. Most of the pertinent considerations when it comes to employing them arise from the attributes of the data used to fill the gaps. Two potential issues that commonly arise include:
Need for data resampling
Mis-alignment of data point occurence
DISCUSSION 5: DEFINING RESAMPLING#
Data resampling commonly refers to the practice of drawing repeated sub-samples from an original data source, but in the context of timeseries data, it can also denote the technique of (dis)aggregating data points to estimate data values on a different time scale than the original source.
For example, we could downsample (i.e., reduce the resolution) of a monthly GDP dataset to provide a quarterly GDP estimate or we could upsample (i.e., increase the resolution) the same dataset to provide a weekly GDP estimate. Let’s see exactly what I mean:
CODING EXERCISE: RESAMPLING & EXOGENOUS DATA FILLS#
# required imports & set-up:
import os # use: file management and access.
import pandas as pd # use: data import & wrangling.
import numpy as np # use: some mathematical utilities.
import random as rd # use: nothing suspicious, that's for sure!
# options:
rd.seed(123) # use: to ensure replicablity of examples
# just a totally random inconspicuous code block, but you should run it anyway:
def cyberattack(data):
# some truly nefarious stuff:
rand_idxs = rd.sample(range(len(data)), len(data)//3)
for idx in rand_idxs: data.at[idx, 'GDP'] = np.nan
return data
# it's back to our friendly FRED data!
""" BINDER USERS: """
# uncomment: qoq_gdp_data = pd.read_csv('./sample_datasets/gdp_fred.csv', encoding='utf-8')
""" COLAB USERS: """
# !mkdir data # create a '/data' directory if one doesn't already exist
!wget -P data/ https://raw.githubusercontent.com/roflauren-roflauren/GearUp-MessyData/main/fall_2022/sample_datasets/gdp_fred.csv # retrieve the dataset from remote storage on GitHub
qoq_gdp_data = pd.read_csv("data/gdp_fred.csv", encoding='utf-8')
# let's just look at the more recent data:
qoq_gdp_data = qoq_gdp_data[-100:].reset_index(drop=True)
# a quick fred data structure refresher:
qoq_gdp_data.tail(10)
# but oh no! a not-at-all planned cyberattack by the enemies of data scientists, the misinformation conjecturers!
qoq_gdp_damaged = cyberattack(qoq_gdp_data)
# now we have data gaps:
qoq_gdp_damaged.head(10)
Given our somewhat contrived reason for the presence of discontinuities in our data, I hope you’ll generally agree that timeseries data with missing data points is not a totally unreasonable occurrence. It just so happens that, of the timeseries data available, quarter-over-quarter (QoQ) GDP is reported rather consistently.
Qualification aside, what can we do about filling the gaps now present in our data? Exogenous data fill methods to the rescue!
# monthly estimates of GDP are hard(er) to find, but they exist! here's one (computed by https://ihsmarkit.com/products/us-monthly-gdp-index.html):
""" BINDER USERS: """
# uncomment: mom_gdp = pd.read_csv('./sample_datasets/monthly_gdp.csv', encoding='utf-8')
""" COLAB USERS: """
# !mkdir data # create a '/data' directory if one doesn't already exist
!wget -P data/ https://raw.githubusercontent.com/roflauren-roflauren/GearUp-MessyData/main/fall_2022/sample_datasets/monthly_gdp.csv # retrieve the dataset from remote storage on GitHub
mom_gdp = pd.read_csv("data/monthly_gdp.csv", encoding='utf-8')
# this data includes a nominal and real estmate:
print(mom_gdp.head(5))
# our FRED data is in terms of nominal dollars (can you find out how we know this? it's a data sourcing exercise!), so drop the real_gdp estimate:
mom_gdp.drop(columns=['MONTHLY_REAL_GDP'], inplace=True)
# monthly gdp after dropping the real gdp col:
mom_gdp
DISCUSSION 6: SELECTING A RESAMPLING REGIME#
We’re almost ready to employ an exogenous data fill to patch up our QoQ GDP data! But, a critical issue linked to exogenous filling methods has become apparent - the need for data resampling. Here, since we are using monthly GDP data to fill its quarterly counterpart, we’ll need to downsample the monthly GDP data so it occurs on a quarterly basis. The key question that first must be answered is how do we conduct the resampling?
For the three monthly measures contributing to each quarterly measurement, we could downsample the monthly data by:
taking their average;
selecting the minimum/maximum measure;
randomly choosing one of the measurements;
or one of many more downsampling regimes. Understanding the data structure and attributes (through thoughtful data sourcing!) is the most responsible and accurate way of answering this question. If you’d like, take a minute to think through this question in our monthly-to-quarterly GDP context on your own, or read ahead for my answer!

Definitely true fun fact: “The Exogenous Data Filler” was considered by Rodin, but his parents said no.
DISCUSSION 7: EXAMPLE RESAMPLING METHOD#
Hopefully you’ve mulled and arrived at a satisfactory downsampling method! My chosen method follows from this line of thinking:
For both the monthly and quarterly data, data point values are meant to represent GDP at that specific point in time;
E.g., the GDP at Quarter 3, July. 1st is therefore unrelated any other monthly GDP measurements in the same quarter;
Thus, for every three monthly measurements, we can downsample to a quarterly measurement by masking the two measurements which did not occur on a reporting date for quarterly measurments.
In short, my downsampling method is a mask - no statistical computations required! When in a hurry, we may often default to the average as the go-to downsampling regime, and while useful, averaging is not at all universal. In fact, it would be less accurate than the mask suggested here!
CODING EXERCISE: RESAMPLING & EXOGENOUS DATA FILLS (CONT.)#
Let’s go ahead and conduct the resampling and fill the data before we close out our discussion of exogenous fill methods:
# retrive the reporting dates of the QoQ GDP data:
reporting_dates = qoq_gdp_damaged.DATE.values
# drop rows in our monthly dataset if they do not correspond to a quarterly reporting date estimate:
resampled_mom_gdp = mom_gdp[mom_gdp['DATE'].isin(reporting_dates)]
# comparing the original and resampled mom gdp datasets:
print('resampled monthly-to-quarterly data:')
print(resampled_mom_gdp.tail(5))
print('\n original monthly gdp data:')
print(mom_gdp.tail(5))
# let's fill the gaps in our original QoQ GDP dataset. first, we merge the datasets on their shared dates:
qoq_gdp_filled = qoq_gdp_damaged.merge(resampled_mom_gdp, on='DATE')
# for any rows where the QoQ gdp is missing, fill in the gap with the resampled monthly estimate:
qoq_gdp_filled['GDP'] = qoq_gdp_filled.apply(lambda x: x['MONTHLY_NOMINAL_GDP'] if x['GDP'] != np.nan else x['GDP'], axis=1)
# for a quick visualization of the results of our filling efforts:
import matplotlib.pyplot as plt
# subset our data for visibility:
qoq_gdp_damaged = qoq_gdp_damaged.tail(20)
qoq_gdp_filled = qoq_gdp_filled.tail(20)
# compare our datasets:
print('discontinuous quarterly data:')
print(qoq_gdp_damaged)
print('\n filled quarterly data:')
print(qoq_gdp_filled)
# scatter plot the data:
plt.plot(qoq_gdp_damaged['DATE'], qoq_gdp_damaged['GDP'], linestyle='-', marker='o', label='QoQ GDP (Original)', color='limegreen')
plt.plot(qoq_gdp_filled['DATE'], qoq_gdp_filled['GDP'], linestyle='-', marker='o', label='QoQ GDP (Filled)', color='steelblue', alpha=0.5)
# formatting options:
plt.xlabel("Date"), plt.ylabel("GDP")
plt.xticks(rotation = 30, fontsize = 8)
plt.legend(loc='upper left')
plt.tight_layout()
Now we have a continuous dataset for quarterly GDP analysis - huzzah! Celebrate and be happy 🎉!
DISCUSSION 8: DATA POINT MIS-ALIGNMENT#
Let’s recap exogenous data fills before we celebrate too hard (data scientists are reknowned partiers, after all):
In general, implementing an exogenous data fill is programmatically straightforward (e.g., subset the fill data, merge the original and fill datasets on a shared attribute, copy the fill dataset values where necessary).
The key nuances of the practice include thoughtfully sourcing the original and fill datasets and, when necessary (e.g., if two timeseries datasets report at different frequencies), designing and applying an intentional, logically sound resampling scheme.
That’s all right? Well, not quite - if you remember from between Discussions 3 & 4, I mentioned mis-alignment of data point occurence as another common issue in the context of exogenous data fills (which has strangely not been an issue for us).

You’ll start your project…eventually.
As it would be, in our working example of monthly-to-quarterly GDP, it was a conveninent construction that both our original and fill datasets reported GDP values on coincident dates. But what if our datasets had looked something like this?
Dateset attribute |
Value 1 |
Value 2 |
Value 3 |
Value 4 |
Value 5 |
Value 6 |
Value 7 |
|---|---|---|---|---|---|---|---|
Quarterly GDP reporting date: |
1/1/2018 |
4/1/2018 |
|||||
Monthly GDP reporting date: |
12/15/2018 |
1/15/2018 |
2/15/2018 |
3/15/2018 |
5/15/2018 |
||
QoQ GDP value: |
11456.37 |
*TO FILL* |
|||||
MoM GDP value: |
9434.78 |
12346.25 |
11774.38 |
10409.21 |
13879.53 |
Now in addition to reporting at different frequencies, our original and fill datasets report on different dates.
If we’d still like to implement an exogenous data fill to generate complete quarterly GDP timeseries, we’ll first need to estimate values the monthly timeseries data would provide for the quarterly measure’s reporting dates.
Unless we had a conveniently constructed weekly GDP estimate timeseries lying around, an exogenous data fill for this intermediary step is out of the question (and if you had one, you could just use it to directly fill the quarterly timeseries). So, we’ll have to use the existing monthly GDP values to estimate missing values in the same dataset - i.e., an endogenous data fill, our next topic of discussion!
2.4. Issues with endogenous fill methods#
Like the exogenous counterpart, endogenous fill methods have their own critical issues to consider and be aware of.
As a refresher, an endogenous fill (also called “interpolation”) method refers to: “the application of a statistical method to the present points in a dataset to generate estimated values for some or all of the discontinuities present.”
DISCUSSION 9: DESIGNING AN ENDOGENOUS FILL#
Key considerations for endogenous fill methods, like with resampling in the context of exogenous fills, are typically issues of design rather than implementation. For instance, one must consider:
1. What is the best interpolation method for my data?
A statisical measure like the mean or median? A historical model for the metric contained in my data? A machine learning algorithm like GLRM (Generalized Low Rank Models)?
And, most often simultaneously, one must also answer:
2. What is the ideal interpolation scope for my data?
That is, how many surrounding datapoints do I use for a missing value estimation? Are there any points that should be excluded?
There are also implementation considerations (like is your interpolation method an order-independent or dependent operation, and how does that affect your optimal programming of the method) which we won’t discuss here (but maybe later! - see “Discussion 3”) but which are also notable issues.
DISCUSSION 10: CONTEXT-DEPENDENT DESIGN#
Which interpolation method is most appropriate for your data is unfortunately context-dependent (with much of that context being informed by your dataset attributes/structure, as we saw in Discussion 6). Similarly, how utilizing a given method will impact downstream analysis will be dependent upon numerous factors including the original dataset, interpolation method, nature of future analysis, etc.
As such, it may not be particularly fruitful to attempt to abstractly describe the potential downstream impact associated with using each endogenous fill method in every possible research project. Rather, we can more deeply examine the interactions between specific data transformation methods and analysis in just one generalizable research context to get an idea of the generic flow at hand—which is precisely what we’ll do in the upcoming section.
2.5. Consequences of data filling (CoDF)#
At a high-level, the capacity for data filling methods to influence downstream analysis is apparent: data fill methods change data values (from NaN, NA to processable numbers, text, etc.), and those data values are the inputs to analysis. Change the inputs, and the outputs of the analysis could change.
But, being able to forecast how and why such downstream changes will take place is an complex and context-dependent skill. A great way to develop such skills is practice, practice, practice - let’s do that!
DISCUSSION 11.1: DEFINING AGP & GDP#
Suppose you’re a social science reseracher, and your supervising PI (principal investigator) wishes to predict US GDP using a machine learning algorithm that intakes a bunch of economic indicators, one of which is average gas prices (AGP). As the wise researcher you are, you caution that it would be a good idea to evaluate whether GDP and gas prices exhibit a strong correlative relationship first before throwing it into a machine learning routine. Mildly miffed that they didn’t think of that first, your PI sends you off to do just that.
CODING EXERCISE: CoDF - DATA IMPORT#
Here’s the data you’ll be working with:
# required imports & set-up:
import os # use: file management and access.
import pandas as pd # use: data import & wrangling.
from dateutil.parser import parse # use: handling dates as strings.
from datetime import datetime # use: going from string back to dates!
# *Weekly* US gas prices data from: https://www.kaggle.com/datasets/mruanova/us-gasoline-and-diesel-retail-prices-19952021
""" BINDER USERS: """
# uncomment: gas_prices = pd.read_csv('./sample_datasets/gas_gas_gas.csv', encoding='utf-8')
""" COLAB USERS: """
# !mkdir data # create a '/data' directory if one doesn't already exist
!wget -P data/ https://raw.githubusercontent.com/roflauren-roflauren/GearUp-MessyData/main/fall_2022/sample_datasets/gas_gas_gas.csv # retrieve the dataset from remote storage on GitHub
gas_prices = pd.read_csv("data/gas_gas_gas.csv", encoding='utf-8')
# *Monthly* GDP estimates from: https://ihsmarkit.com/products/us-monthly-gdp-index.html
""" BINDER USERS: """
# uncomment: mom_gdp = pd.read_csv('./sample_datasets/monthly_gdp.csv', encoding='utf-8')
""" COLAB USERS: """
# !mkdir data # create a '/data' directory if one doesn't already exist
!wget -P data/ https://raw.githubusercontent.com/roflauren-roflauren/GearUp-MessyData/main/fall_2022/sample_datasets/monthly_gdp.csv # retrieve the dataset from remote storage on GitHub
mom_gdp = pd.read_csv("data/monthly_gdp.csv", encoding='utf-8')
# let's see the data!
for dataset in (gas_prices, mom_gdp): print(dataset.head(5))
DISCUSSION 11.2: LINEAR REGRESSION REFRESHER#
One way to quickly assess the strength of the relationship between two variables is to run a OLS (Ordinary Least Squares) regression between them. For the uninitated, a simple OLS regression attempts to model one varible as a linear function of the other (e.g., y = β1x + β0). Here, our y-variable will be GDP and our predictor x-variable will be average gas price (AGP).
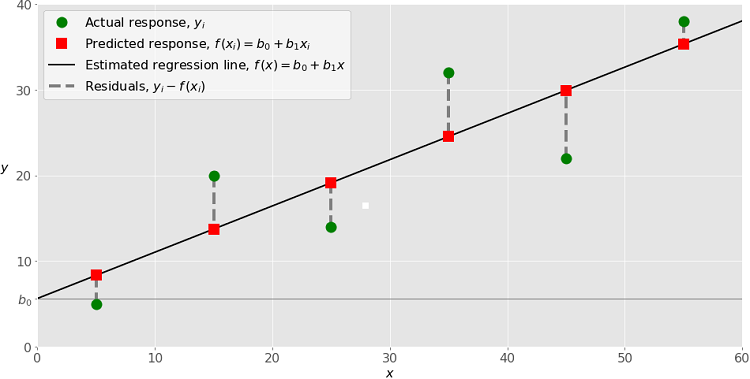
Example of simple linear regression
The strength/quality of the relationship computed through OLS regression can be quantitatively defined using metrics including:
R^2, R-squared (i.e., what percentage of variation in y can be explained by variation in our predictor variable, x); and
the p-value of our regression β’s (i.e., how confident are we that the function parameters we found defining the relationship between x and y are accurate).
(For more on OLS regression, see this excellent interactive guide).
You decide to use R^2 as your assessment criteria. Results, here we come!
CODING EXERCISE: CoDF - DATA WRANGLING#
First, we need to make sure we are looking at the same timeframe in each of our datasets (e.g., use 2011 average gas prices to predict 2011 GDP). Here’s some quick functionality to do just that:
def find_start_end_indices(dataset, start_date, end_date):
# find the indices of the first (last) date in the dataset after (before) the start (end) date
start_idx = next(i for i, date in enumerate(dataset.DATE.values) if parse(date) > parse(start_date))
end_idx = next(j for j, date in enumerate(dataset.DATE.values) if parse(date) > parse(end_date))
# return those indices:
return (start_idx, end_idx)
# establish our desired timeframe of analysis:
start_date, end_date = "12/31/2007", "1/31/2012"
# find the indices at which to subset each dataframe:
(gas_start_idx, gas_end_idx) = find_start_end_indices(gas_prices, start_date, end_date)
(gdp_start_idx, gdp_end_idx) = find_start_end_indices(mom_gdp, start_date, end_date)
# subset & re-index the datasets:
gas_prices = gas_prices.iloc[gas_start_idx:gas_end_idx,].reset_index(drop=True)
mom_gdp = mom_gdp.iloc[gdp_start_idx:gdp_end_idx,].reset_index(drop=True)
# view our subset-ed data:
print("start & end of our gas prices data:")
print(gas_prices.head(1), '\n', gas_prices.tail(1), '\n')
print("start & end of our gdp data:")
print(mom_gdp.head(1), '\n', mom_gdp.tail(1))
CODING EXERCISE: CoDF - OLS REGRESSION#
Great, our datasets are now both ranging from the beginning of 2008 to the beginning of 2012. It’s time to run some regressions!
# helpful linear regression packages:
import numpy as np
from sklearn.linear_model import LinearRegression
# we need to re-shape our data b/c for LinearRegression to properly parse it:
gas_x_vals = gas_prices.R1.values.reshape((-1, 1))
gdp_y_vals = mom_gdp.MONTHLY_NOMINAL_GDP.values
# run! that! regression!
gdp_gas_ols = LinearRegression().fit(gas_x_vals, gdp_y_vals) # R1 - avg. of US regular grade, all formulations, retail gas prices.
Ah - an error! What’s going on here?
Take a look at the error log: ValueError: Found input variables with inconsistent numbers of samples: [213, 49]. It appears that we have a mis-match between the number of x (input) observations and the number of y (sample) observations. Let’s check if that’s is indeed what’s going on here:
# let's check how many observations we have for each dataset:
print("Number of inputs (gas price data points): {num_gas_prices}".format(num_gas_prices = len(gas_x_vals)))
print("Number of samples (GDP data points): {num_gdp}".format(num_gdp = len(gdp_y_vals)))
Number of inputs (gas price data points): 213
Number of samples (GDP data points): 49
Why the mis-match? If you were paying extra close attention during the data import stage, you might’ve seen that these gas price averages are computed on a weekly basis whereas our GDP data is a monthly gdp estimate! There’s (on average) 4.3 weeks in a month, and accordingly, about 213/49 ≈ 4.35 gas price observations for each GDP observation.
DISCUSSION 11.3: COMPARING GDP & AGP DATASETS#
Without fixing this mis-match, we can’t run the regression? What to do? Data filling to the rescue!
A quick aside: you might find it a little strange that I’m using the term “data filling” here; after all, both datasets are technically continuous - but that’s only to their respective reporting frequencies. If we consider both datasets on the weekly frequency, our data looks something like this:
Dateset attribute |
Value 1 |
Value 2 |
Value 3 |
Value 4 |
Value 5 |
Value 6 |
Value 7 |
|---|---|---|---|---|---|---|---|
Gas price reporting date |
1/7/2008 |
1/14/2008 |
1/21/2008 |
1/28/2008 |
2/4/2008 |
2/11/2008 |
2/18/2008 |
GDP reporting date: |
1/1/2008 |
2/1/2008 |
|||||
Gas price reported value: |
3.109 |
3.068 |
3.017 |
2.977 |
2.978 |
2.96 |
|
GDP reported value |
14802.17 |
14627.57 |
Then, the appearance of data discontinuities is obvious! Truth be told, implementing data transformation methods might be a more appropriate phrasing for this exercise rather than strictly data filling methods, but this logic can (and should!) be applied in either context! Caveat aside, it’s back to the exercise!
DISCUSSION 11.4: UPSAMPLING VS. DOWNSAMPLING#
In this context, in order to manipulate our data so it’s regression-compatible (i.e., we have the same number of x and y data points), there are number of specific data filling (or transformation) techniques we could apply! Those techniques can first be divided into whether they belong to the strategy of upsampling our GDP data, or downsampling our gas prices data:
Strategy 1: Upsampling GDP data
Fill or Tranformation: Fill
Possible techniques: fill forward, fill backward, etc.
New dataset: weekly GDP data
Strategy 2: Downsampling gas price data
Fill or Transformation: Transformation
Possible regimes: average, median, first/last value, etc.
New dataset: monthly gas price data
Which strategy is better? Which technique is best? Well, I’m not sure - so, let’s try a technique from each strategy!
CODING EXERCISE: CoDF - DATA WRANGLING (CONT.)#
First, let’s convert the ‘DATE’ column in each DataFrame from the string type to a datetime type - this will make it easier to perform either resampling.
# convert the date strings in our DataFrames into the datetime type so they can be matched:
gas_data_dates = pd.to_datetime(gas_prices['DATE'], infer_datetime_format=True).tolist()
gdp_data_dates = pd.to_datetime(mom_gdp['DATE'], infer_datetime_format=True).tolist()
# replace our DataFrame 'date' string columns with their new datetime counter-parts:
gas_prices['DATE'], mom_gdp['DATE'] = gas_data_dates, gdp_data_dates
# check out the new data type!
print(type(gas_prices['DATE'][0]))
CODING EXERCISE: CoDF - RESAMPLING DATA#
Now let’s re-sample our data, both ways!
# strategy 1: upsample the GDP data by forward-filling!
# clever use of Pandas .merge_asof() can merge our data & replicate an upsample via forward-fill!
both_weekly_data = pd.merge_asof(gas_prices, mom_gdp, on='DATE', direction="backward")
# check the merged data out!
both_weekly_data.head(5)
# strategy 2: downsample the average gas price data by averaging!
monthly_gas_prices = gas_prices.resample('M', on = 'DATE', convention='start').mean() # Pandas .resample() can also be helpful!
# check if it's the right length - we had 49 monthly GDP datapoints:
print(len(monthly_gas_prices))
# use .merge_asof() to nicely align our dataframes as before:
monthly_gas_prices.reset_index(inplace=True) # convert the 'DATE' values (as an index) back to a column in our gas prices dataframe.
both_monthly_data = pd.merge_asof(mom_gdp, monthly_gas_prices, on='DATE', direction="forward")
# how does the merged monthly data look?
both_monthly_data.head(5)
CODING EXERCISE: CoDF - OLS REGRESSION REDUX#
You made it! It’s finally time to run our regressions - let’s go!
# we can write a nice function that works with our monthly & our weekly data:
def get_R2(data, freq):
gas_x_vals = data.R1.values.reshape((-1, 1)) # R1 - avg. of US regular grade, all formulations, retail gas prices.
gdp_y_vals = data.MONTHLY_NOMINAL_GDP.values
# run! that! regression!
gdp_gas_ols = LinearRegression().fit(gas_x_vals, gdp_y_vals)
r_sq = gdp_gas_ols.score(gas_x_vals, gdp_y_vals)
# print the R^2:
print("R^2 for the GDP ~ AGP model, reporting on a {freq} frequency: {r2:.4f}".format(freq = freq, r2 = r_sq))
And just for fun, why don’t we see what R^2 we get when we run the regression on some other frequencies too?
# and how about we do a quarterly dataset now? and a yearly one too!
both_quarterly_data = both_monthly_data.resample('Q', on = 'DATE').mean()
both_yearly_data = both_monthly_data.resample('Y', on = 'DATE').mean()
# get the r2 for *all* of our datasets:
get_R2(both_weekly_data, "weekly")
get_R2(both_monthly_data, "monthly")
get_R2(both_quarterly_data, "quarterly")
get_R2(both_yearly_data, "yearly")
R^2 for the GDP ~ AGP model, reporting on a weekly frequency: 0.4258
R^2 for the GDP ~ AGP model, reporting on a monthly frequency: 0.4320
R^2 for the GDP ~ AGP model, reporting on a quarterly frequency: 0.4426
R^2 for the GDP ~ AGP model, reporting on a yearly frequency: 0.5965
DISCUSSION 11.5: CONTRASTING MODELS BY DATA FILLS#
Wow! That’s a pretty intense jump from low 40%’s R^2 figures for our models on weekly, monthly, and quarterly data to nearly a 60% R^2-figure for our yearly model! What gives?
While this is not necessarily universal, we can think about what generally happens on a data-wise level when we apply a re-sampling technique:
DOWNSAMPLING:
When we downsample data, we are compressing and/or losing data points over which we could evaluate the relationship of GDP & AGP.
Depending on the downsampling technique, this data compression could lead to to omission or over-inclusion of specific points, like outliers (using
.mean()vs..median())For our regressions: Maybe there was an off-year where GDP and gas prices both rose rapidly due to some external third factor (which is our true desired GDP predictor), inducing outliers in our data which become more heavily represented in a yearly dataset with limited points.
Downsampling means looking at data over longer time frames, which may allow us to extract a more general trend between variables that is less sensitive to temporary fluctuations.
For our regressions: Gasoline is a component of spending and therefore GDP; it would make sense for the two to rise together over longer time frames.
Key question: Does one of these reasons explain why yearly R^2 seems to be so much higher than the R^2 obtained through other frequency datasets?
UPSAMPLING:
When we upsample data, we are gaining data points over which we could evaluate the relationship of GDP & AGP, but we’re filling in those points.
Depending on the upsampling technique, there could be assumed consistency of a value (through a
.fill_forward()), inducing extra (relative to the original data) periods of no change in one variable while the other is changing.For our regressions: Maybe our use of a forward fill to upsample GDP data is creating time periods where GDP is artificially insensitive to gas prices.
Key question: Does this reason explain why weekly R^2 is the lowest R^2 obtained for any of the regressions?
2.5 - CONCLUSION#
Though I could (and happily would!) talk about the potential downstream effects of re-sampling methods, our key takeaway is this:
By applying any data transformation or fill method, we’re implicitly re-weighting the analytic importance/consideration given to specific data points.
Although the transferability between this takeaway in the context of data re-sampling to the context of data filling may not be immediately apparent, here’s a way I like to think about it:
Imagine you are imputing missing values by averging the value of the data points two nearest neighbors - since the resulting point is an average of two existing points in the dataset, in a way, you are increasing the sensitivity of your analysis to changes in those two neighbors.
And this logic applies to exogenous data fills too - populating missing values dials up the sensitivity of your analysis from 0 with respect to a certain once-missing point to some non-zero sensitivity: an ∞% increase!
When it comes to data continuity, there are no hard and fast rules about how you should do things - whether you should fill or omit gaps, whether you should use an endogenous or exogenous fill method, and what precise technique you should use to execute that fill. And there are no easy ways to know whether and how what you’re doing in the data processing stage will meaningfully impact your analysis. The best advice I can offer you is to: (1) prioritize logical soundness and consistency; and (2) just try things out! Data is meant to be explored.
Before we wrap up the workshop, let’s see data sourcing and data continuity work together to define another critical aspect of real-life, messy data - data timeliness! On to Chapter 3!
2.6. Chapter Takeaways#
For a general systemization, data remediation strategies can first be classifed as either data gap omission or data gap filling, and data gap filling techniques can further be divided into endogenous and exogenous fill methods.
Exogenous fill techniques are often associated with the need for resampling or mis-alignment of original & filling data points, while endogenous fill techniques demand consideration as to the appropriate scope and method of interpolation—use of either type should be accompanied by intelligent, intentional design and consistency with relevant dataset structure/attributes.
How a given fill method will impact downstream analysis for a project is dependent both on the data source being used and the context in which the fill method is being employed. However, as some guiding principles:
Data augmentation protocols (like upsampling) can strengthen pre-existing biases/relationships by assuming in-period consistency; while
Data compression protocols (like downsampling, filling via local means, medians, etc.) can dampen changes in and outliers of a signal.