Chapter 3 - Data Timeliness
Contents
Chapter 3 - Data Timeliness#

Chapter preview#
Learning objectives#
Define data timeliness and identify data timeliness practices.
Contextualize data timeliness as an intersection of prior data robustness dimensions.
Key question: When is data present-ness important, and how do we manufacture it when not readily available?
Chapter prerequisites: Python imports#
No coding (or associated imports) is required for this chapter.
3.0. Defining “data timeliness”#
As a final consideration, let’s briefly discuss data timeliness:
Data timeliness refers to the proximity of utilized data to the present moment and/or relevant analysis and projections.
In general (can you think of exceptions?), more timely data is preferred; e.g., an NLP analysis on the most promient topics in 1970’s highschool science textbooks should avoid use of a text corpus of 1950’s textbooks.
Note: The following discussion of data timeliness is most relevant to time series data. Limited applicability to other types of data should be noted.
DISCUSSION 1: TYPES OF DATA TIMELINESS PRACTICES#
Data timeliness practices can broadly be divided into two categories:
assessing data timeliness; and
constructing data timeliness.
The former category, while important, is mostly an exercise in identifying the structural qualities of potential datasets and is highly related to data sourcing and continuity; e.g.,
Do you opt for data resource A or data resource B when resource B is more reputable but less timely?
Is it better to use data resource X or data resource Y when resource Y is more timely but also subject to more frequent data gaps?
Assessing data timeliness is usually a qualitative, ad hoc practice, so there are limited hard-and-fast rules to apply when selecting between more or less timely datasets.
However, constructing data timeliness for a given data resource is a means to mitigate some potential tradeoffs associated with using that resource — and it’s what we’ll be discussing next!
3.1. Constructing data timeliness#
Consider the applications of your project are research - are you trying to build a time-sensitive indicator? Derive a key statistic to motivate decisions? Make a near real-time prediction?
In such scenarios, data timeliness is especially crucial. Utilizing data resources that are frequently updated is a must. But, if such data resources do not exist, timeliness can be constructed:
For instance, consider GDP. The most accurate GDP data is published a quarter after the relevant point of measurement (e.g., final 2021 Q3 measurements are published at the end of 2021 Q4).
If official advance measurements weren’t published (though they are), you could construct your own by estimating GDP from a more timely data resource; e.g., credit card spending.
Constructing a more timely estimate in this way is essentially an exercise in identifying a leading indicator and quantifying its relationship with your metric of interest:
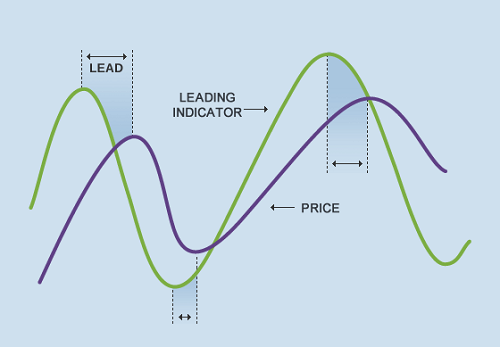
Leading indicators predict changes in a given signal.
And best of all, this exercise is one we already have familiarity with!
Selecting and sourcing an indicator is an iteration of the data sourcing process; and
Quantifying the relationship between the indicator and metric of interest is a type of present-moment data (dis)continuity remediation.
3.2. Chapter Takeaways#
If you want to develop experience with all of the practices reviewed in this workshop—data sourcing, data continuity, and data timeliness—attempting to construct your own timely estimate of GDP data is highly recommended!
Otherwise, this chapter concludes the initial GearUp workshop materials! Stay posted for more workshops from SSDS, and please schedule a consult with SSDS to further explore data best practices or for any other of your data science needs. Thank you 😊!